Generating Scaling Relations with XGA
This tutorial will explain how to generate XGA scaling relations objects, and go through some of their key useful features. Generating scaling relations that map difficult-to-measure parameters onto values that are easier to determine is very common in cluster science, with mass-temperature, luminosity-temperature, and luminosity-richness relations being just a few that spring to mind.
As such I created this class of product, ScalingRelation, as well as several independent fitting method to generate them from arbitrary data. This part of XGA can almost be viewed as a submodule within the main module, as you do not have to use the source and sample structure to generate relations, the data can be supplied from an external source, and the fitting process will work exactly the same.
[1]:
import pandas as pd
from astropy.units import Quantity, pix
from astropy.cosmology import Planck15
import numpy as np
from xga.samples.extended import ClusterSample
from xga.sas import evselect_spectrum, emosaic
from xga.xspec import single_temp_apec
from xga.models.misc import power_law
from xga.relations.fit import scaling_relation_lira, scaling_relation_odr
from xga.relations.clusters import LT, Lλ, MT
from xga.products.relation import ScalingRelation
Relation quality disclaimer
All of the relations we generate here are for demonstration purposes only, they should not be used for any real scientific purposes.
Defining our sample
I am again using clusters from the XCS-SDSS sample, they will be used to demonstrate the fitting and visualisation of scaling relations from an XGA ClusterSample object. I have read in their information from a file as I did not want to include a large table of irrelevant information in one of the cells of this tutorial. This time I will be using fourty randomly chosen clusters rather than four, as we could not reasonably hope to get a good fit with such a small sample.
[2]:
sample = pd.read_csv("modified_xcssdss_sample.csv", header="infer").sample(40)
srcs = ClusterSample(sample["RA_xcs"].values, sample["DEC_xcs"].values, sample["z"].values,
sample["name"].values, r500=Quantity(sample["r500"].values, 'arcmin'),
clean_obs=True, clean_obs_reg="r500", load_fits=False, psf_corr=False,
richness=sample['richness'].values, richness_err=sample['richness_err'].values)
Declaring BaseSource Sample: 100%|██████████| 40/40 [00:35<00:00, 1.13it/s]
Generating products of type(s) image: 100%|██████████| 3/3 [00:03<00:00, 1.19s/it]
Generating products of type(s) ccf: 100%|██████████| 95/95 [02:43<00:00, 1.72s/it]
Generating products of type(s) expmap: 100%|██████████| 3/3 [00:38<00:00, 12.93s/it]
Generating products of type(s) image: 100%|██████████| 40/40 [01:03<00:00, 1.59s/it]
Generating products of type(s) expmap: 100%|██████████| 40/40 [00:40<00:00, 1.01s/it]
Setting up Galaxy Clusters: 0%| | 0/40 [00:00<?, ?it/s]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-31144 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 2%|▎ | 1/40 [00:10<07:02, 10.83s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/extended.py:180: UserWarning: A point source has been detected in 0728170101 and is very close to the user supplied coordinates of XCSSDSS-165. It will not be excluded from analysis due to the possibility of a mis-identified cool core
warnings.warn("A point source has been detected in {o} and is very close to the user supplied "
Setting up Galaxy Clusters: 5%|▌ | 2/40 [00:12<05:06, 8.06s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-2 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 10%|█ | 4/40 [00:16<02:56, 4.91s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/extended.py:180: UserWarning: A point source has been detected in 0601260201 and is very close to the user supplied coordinates of XCSSDSS-10401. It will not be excluded from analysis due to the possibility of a mis-identified cool core
warnings.warn("A point source has been detected in {o} and is very close to the user supplied "
Setting up Galaxy Clusters: 22%|██▎ | 9/40 [00:23<00:58, 1.87s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-1174 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 28%|██▊ | 11/40 [00:27<00:59, 2.06s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:84: UserWarning: There are 1 alternative matches for observation 0109080301, associated with source XCSSDSS-14715
warnings.warn("There are {0} alternative matches for observation {1}, associated with "
/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-14715 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 30%|███ | 12/40 [00:30<01:00, 2.16s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-8060 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 32%|███▎ | 13/40 [00:33<01:03, 2.36s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:84: UserWarning: There are 1 alternative matches for observation 0404967101, associated with source XCSSDSS-8070
warnings.warn("There are {0} alternative matches for observation {1}, associated with "
/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-8070 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 38%|███▊ | 15/40 [00:51<02:08, 5.14s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-487 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 48%|████▊ | 19/40 [01:00<01:01, 2.93s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-7190 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 52%|█████▎ | 21/40 [01:10<01:09, 3.68s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-4003 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 55%|█████▌ | 22/40 [01:13<01:02, 3.48s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-23 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 65%|██████▌ | 26/40 [01:24<00:35, 2.56s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-382 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 68%|██████▊ | 27/40 [01:27<00:36, 2.79s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-2984 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 70%|███████ | 28/40 [01:47<01:32, 7.74s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/extended.py:180: UserWarning: A point source has been detected in 0404190201 and is very close to the user supplied coordinates of XCSSDSS-10223. It will not be excluded from analysis due to the possibility of a mis-identified cool core
warnings.warn("A point source has been detected in {o} and is very close to the user supplied "
/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-10223 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 75%|███████▌ | 30/40 [02:04<01:14, 7.44s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/extended.py:180: UserWarning: A point source has been detected in 0760230301 and is very close to the user supplied coordinates of XCSSDSS-137. It will not be excluded from analysis due to the possibility of a mis-identified cool core
warnings.warn("A point source has been detected in {o} and is very close to the user supplied "
Setting up Galaxy Clusters: 78%|███████▊ | 31/40 [02:07<00:55, 6.13s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-5077 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 98%|█████████▊| 39/40 [02:24<00:02, 2.35s/it]/home/dt237/code/PycharmProjects/XGA/xga/sources/general.py:99: UserWarning: XCSSDSS-30950 has not been detected in all region files, so generating and fitting products with the 'region' reg_type will not use all available data
warnings.warn("{n} has not been detected in all region files, so generating and fitting products"
Setting up Galaxy Clusters: 100%|██████████| 40/40 [02:28<00:00, 3.70s/it]
Generating products of type(s) image: 100%|██████████| 15/15 [00:03<00:00, 4.06it/s]
Generating products of type(s) expmap: 100%|██████████| 15/15 [00:01<00:00, 7.70it/s]
Measuring cluster properties
Just as in our last tutorial ‘Spectroscopy with XGA’, we’re going to generate spectra in the R\(_{500}\) region for all the sources, and then fit them with a single temperature absorbed APEC model. This will give us the temperature and luminosity of all the clusters in the sample, which will allow us to build a scaling relation as a demonstration of XGA’s capabilities:
[3]:
# This command generates spectra for all the clusters in our sample, in their R500 regions
srcs = evselect_spectrum(srcs, 'r500')
Generating products of type(s) spectrum: 100%|██████████| 164/164 [2:56:28<00:00, 64.57s/it]
[4]:
# And this fits a single temperature APEC model to them
srcs = single_temp_apec(srcs, 'r500')
Running XSPEC Fits: 100%|██████████| 40/40 [03:50<00:00, 5.76s/it]
A scaling relation from a ClusterSample
I’ve built convenience functions into the ClusterSample class, which make it very easy to generate certain types of common scaling relation. The only information that the method typically needs is the region for which spectra were generated and parameters measured, though plenty of other information (such as the model used to fit the data) can be supplied. The methods assume that, for a ClusterSample, we would have fit an absorbed APEC model, so that is the default.
Once the method call is complete, an XGA scaling relation product is returned to the user. Note that it is not stored inside the sample object, it goes directly back to the user.
The user is allowed to select the x and y normalisation values that should be used during the fit, and can easily change them from their standard values by passing them into keyword arguments. We have found that, in general, the best results are given when the normalisation is similar to the median value of the dataset.
[5]:
# Making an Lx-Tx relation
lx_tx_relation = srcs.Lx_Tx('r500')
# Making an Lx-richness relation
lx_λ_relation = srcs.Lx_richness('r500')
/home/dt237/code/PycharmProjects/XGA/xga/samples/base.py:242: UserWarning: There are no XSPEC fits associated with XCSSDSS-455
warn(str(err))
/home/dt237/code/PycharmProjects/XGA/xga/samples/extended.py:425: UserWarning: One of the temperature uncertainty values for XCSSDSS-10401 is more than three times larger than the other, this means the fit quality is suspect.
warn("One of the temperature uncertainty values for {s} is more than three times larger than "
/home/dt237/code/PycharmProjects/XGA/xga/samples/extended.py:436: UserWarning: There are no XSPEC fits associated with XCSSDSS-455
warn(str(err))
/home/dt237/code/PycharmProjects/XGA/xga/relations/fit.py:71: UserWarning: 2 sources have NaN values and have been excluded
warn("{} sources have NaN values and have been excluded".format(thrown_away))
/home/dt237/code/PycharmProjects/XGA/xga/relations/fit.py:71: UserWarning: 1 sources have NaN values and have been excluded
warn("{} sources have NaN values and have been excluded".format(thrown_away))
<string>:12: RuntimeWarning: invalid value encountered in power
Viewing scaling relations
Just as with other XGA products, there is a view() method built into the class, to easily create high quality visualisations of the relation. As we generated these relations ourselves, they also have data point associated with them. That is not the case if the scaling relation comes from literature, whether it is one of the ones built into XGA, or one you have defined yourself.
There are several options that change what the output looks like, but one of the main options is the ability to change the figure size, which can be set using the figsize keyword argument:
[6]:
lx_tx_relation.view()
lx_λ_relation.view(figsize=(6, 6))
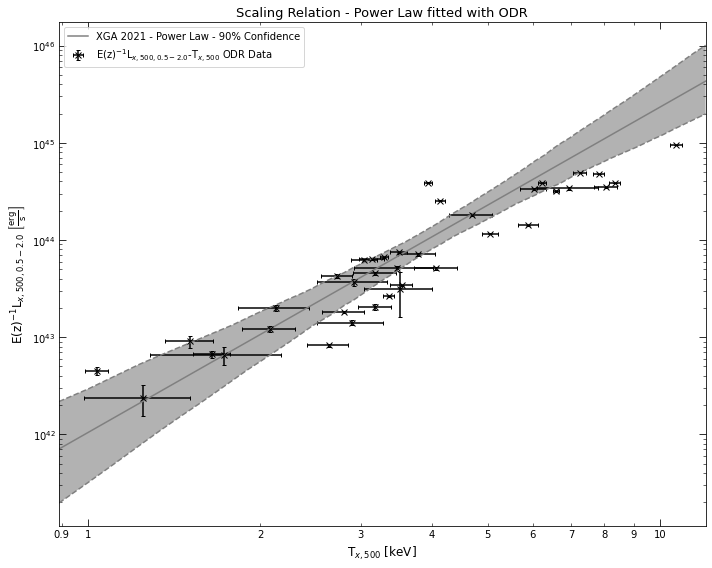
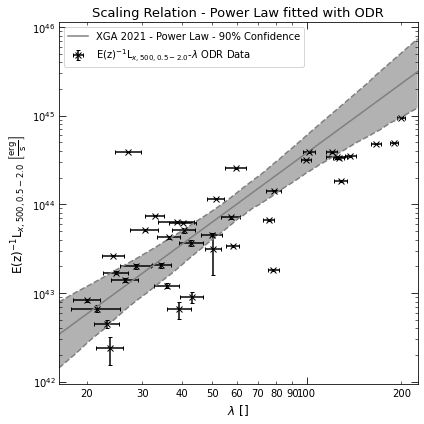
Different fitting methods
I have implemented three different ways to fit these scaling relations, primarily to give the user some choice, though I would highly recommend that you use the implementation of the LIRA fitting package for R (Sereno (2015)) - LIRA is an extremely capable fitting package, and produces excellent results. The downside is that it requires the installation of some optional external dependencies.
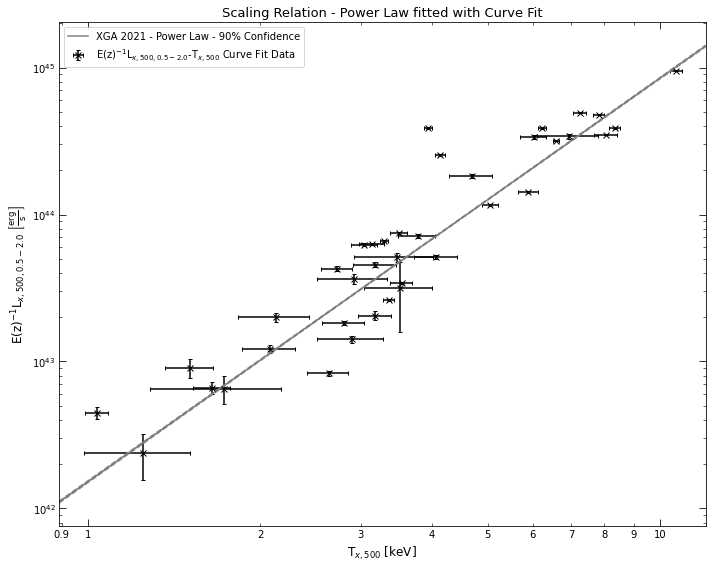
The other methods available are scipy’s simple non-linear least squares implementation (curve_fit), and scipy’s orthogonal distance regression (ODR) implementation. ODR is the default method for ClusterSample scaling relation methods, as it does not require external dependencies, and seems to work quite well.
I’m going to use a ClusterSample Lx_Tx relation as an example, and show how you can change the fitting method when you call the function - all this does is call the different fitting functions in xga.relations.fit:
[7]:
# By setting the fit method to LIRA, we choose to use that instead of the default ODR
lx_tx_relation_lira = srcs.Lx_Tx('r500', fit_method='lira')
# And quickly viewing the relation
lx_tx_relation_lira.view()
# We repeat this process but with scipy's curve_fit
lx_tx_relation_curvefit = srcs.Lx_Tx('r500', fit_method='curve_fit')
lx_tx_relation_curvefit.view()
/home/dt237/code/PycharmProjects/XGA/xga/samples/base.py:242: UserWarning: There are no XSPEC fits associated with XCSSDSS-455
warn(str(err))
/home/dt237/code/PycharmProjects/XGA/xga/samples/extended.py:425: UserWarning: One of the temperature uncertainty values for XCSSDSS-10401 is more than three times larger than the other, this means the fit quality is suspect.
warn("One of the temperature uncertainty values for {s} is more than three times larger than "
/home/dt237/code/PycharmProjects/XGA/xga/samples/extended.py:436: UserWarning: There are no XSPEC fits associated with XCSSDSS-455
warn(str(err))
/home/dt237/code/PycharmProjects/XGA/xga/relations/fit.py:71: UserWarning: 2 sources have NaN values and have been excluded
warn("{} sources have NaN values and have been excluded".format(thrown_away))
R[write to console]: module mix loaded
|**************************************************| 100%
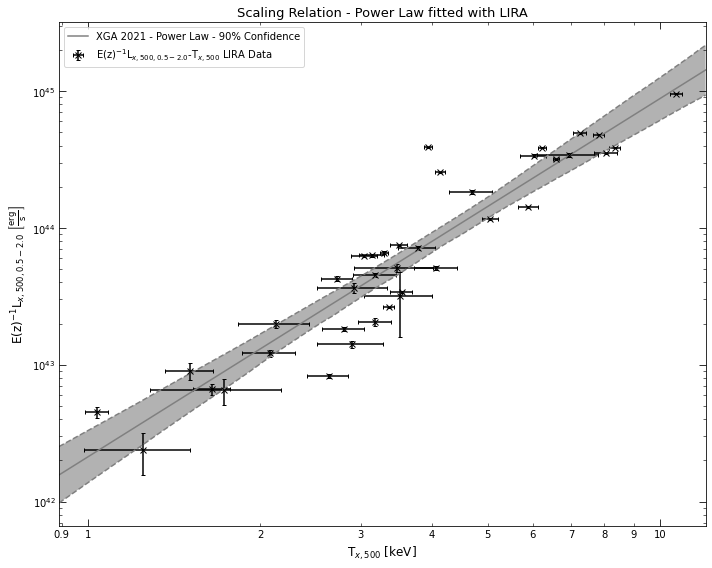
/home/dt237/code/PycharmProjects/XGA/xga/samples/base.py:242: UserWarning: There are no XSPEC fits associated with XCSSDSS-455
warn(str(err))
/home/dt237/code/PycharmProjects/XGA/xga/samples/extended.py:425: UserWarning: One of the temperature uncertainty values for XCSSDSS-10401 is more than three times larger than the other, this means the fit quality is suspect.
warn("One of the temperature uncertainty values for {s} is more than three times larger than "
/home/dt237/code/PycharmProjects/XGA/xga/samples/extended.py:436: UserWarning: There are no XSPEC fits associated with XCSSDSS-455
warn(str(err))
/home/dt237/code/PycharmProjects/XGA/xga/relations/fit.py:71: UserWarning: 2 sources have NaN values and have been excluded
warn("{} sources have NaN values and have been excluded".format(thrown_away))
ScalingRelation objects created using the LIRA fitting method actually have some extra functionality compared to other ScalingRelations. As LIRA is based around the Just Another Gibbs Sampler (JAGS) package, it is an MCMC fitting process, and as such returns parameter chains which it can be useful to visualise.
The output chains are stored in the ScalingRelation on its declaration, and two methods were implemented to generated chain and corner plots:
[8]:
# Here we visualise the parameter chains
lx_tx_relation_lira.view_chains()
# And this shows us a useful corner plot of the parameter space
lx_tx_relation_lira.view_corner()

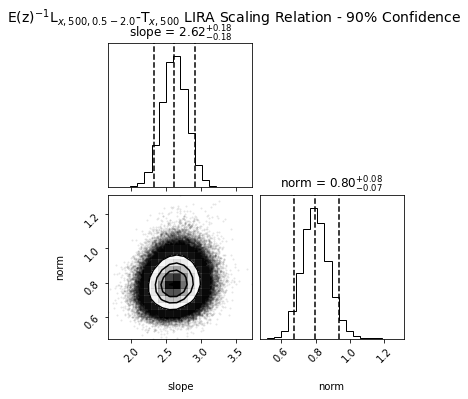
ScalingRelation product properties and making predictions
These product objects are quite simple compared to some of the other products in XGA, but still contain a lot of useful information. The information can be broadly split into two groups; administrative information concerning when the relation was generated, who by etc. (especially useful for relations from literature), and that information concerning the actual properties of the relation, units, the normalisations applied etc.
I will demonstrate a few of the properties using a classic relation from literature that has been built into XGA, the (Arnaud et al. (2005)) mass-temperature relation. As well as visualising the relation, we can also easily access the fit parameters that were used to define it, using the ‘pars’ method; the first column contains the values of all fit parameters, and the second column contains the uncertainty.
[9]:
# Demonstrating the basic adminstrative properties
print(MT.arnaud_m500.year)
print(MT.arnaud_m500.author)
print(MT.arnaud_m500.doi, '\n')
# Viewing the fit parameters that were used to define this scaling relation
print(MT.arnaud_m500.pars)
# We can also easily view the x and y units
print(MT.arnaud_m500.x_unit, MT.arnaud_m500.y_unit)
# And the normalisations
print(MT.arnaud_m500.x_norm, MT.arnaud_m500.y_norm)
2005
Arnaud et al.
10.1051/0004-6361:20052856
[[1.71 0.09]
[3.84 0.14]]
keV solMass
5.0 keV 100000000000000.0 solMass
Once we have a scaling relation, we are also able to make predictions from it, using a built in method that takes an Astropy quantity (with the correct units for the x-axis) as an argument.
The one thing you should remember is that you may need to account for E(z), depending on the relation you have fitted. For instance, the L\(_{\rm{x}}\) - T\(_{\rm{x}}\) relations produced by XGA automatically multiply by the E(z)\(^{-1}\) of each cluster before fitting occurs. As such any values predicted from that relation have an E(z) dependance that must be accounted for to get a physical value:
[10]:
# Defining an astropy quantity in units of keV, to demonstrate the predict functionality
test_temp = Quantity(6, 'keV')
# Getting a prediction of the cluster mass from that test temperature
MT.arnaud_m500.predict(test_temp)
[10]:
Viewing multiple scaling relations
As I mentioned briefly in the ‘XGA Products’ tutorial, ScalingRelation objects have a useful little trick that allows you to easily view different scaling relations on the same axis. As long as two ScalingRelation instances have the same x and y units, you can simply add them together using the Python addition operator. Here I demonstrate this with the L\(_{\rm{x}}\) - T\(_{\rm{x}}\) relation we measured earlier, and an XCS-SDSS L\(_{\rm{x}}\) - T\(_{\rm{x}}\) relation imported from XGA:
[11]:
# Adding them together is extremely easy
comb_lt_relation = lx_tx_relation + LT.xcs_sdss_r500_52
# Then we just call .view() like we would normally
comb_lt_relation.view()
/home/dt237/code/PycharmProjects/XGA/xga/products/relation.py:631: UserWarning: Not all of these ScalingRelations have the same x-axis names.
warn('Not all of these ScalingRelations have the same x-axis names.')
/home/dt237/code/PycharmProjects/XGA/xga/products/relation.py:638: UserWarning: Not all of these ScalingRelations have the same y-axis names.
warn('Not all of these ScalingRelations have the same y-axis names.')
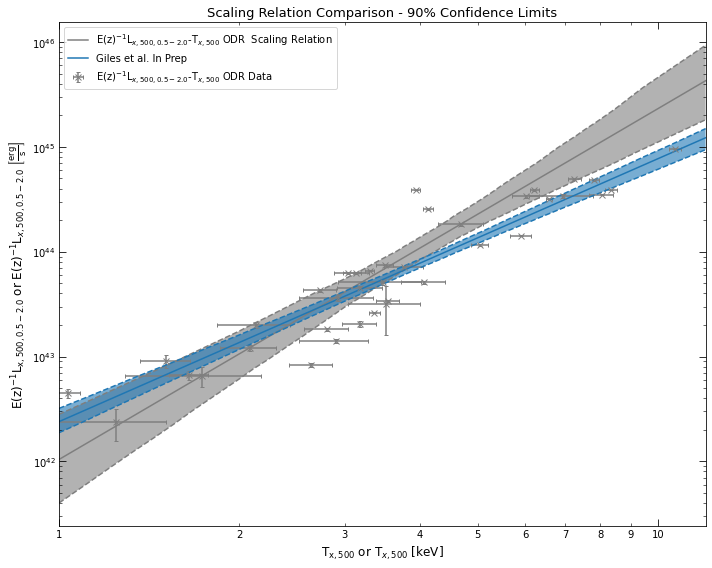
Fitting scaling relations from external data
I tried to think of an interesting dataset that I could generate a scaling relation from as an example, but came up empty, if you can think of an interesting data to use as an example send me an email!
Instead of something interesting, I’m just going to extract some data from our ClusterSample object and show you how to generate a scaling relation manually, using functions imported from xga.relations.fit. We’re going to measure a scaling relation that doesn’t seem particularly useful, \(\lambda\) - T\(_{\rm{x}}\):
[12]:
# Grabbing the temperatures (and temperature errors) from the ClusterSample object
temps = srcs.Tx('r500')
# Printing them on screen
print(temps, '\n')
# And getting the richness values out as well (they only have a gaussian error)
richnesses = srcs.richness
print(richnesses)
[[ 2.13213 0.20519163 0.39433514]
[ 2.80067 0.22927479 0.24261076]
[10.6814 0.20506005 0.29234747]
[ 4.69087 0.39670878 0.41071715]
[ nan nan nan]
[ 6.21681 0.10400441 0.1041854 ]
[ 4.06662 0.33423215 0.36426303]
[ 8.04773 0.37034005 0.37111371]
[ 6.01913 0.31320463 0.31522211]
[ 3.51722 0.35075593 0.61433286]
[ 8.34206 0.18331185 0.18349742]
[ 1.03624 0.04787366 0.04563837]
[ 3.35933 0.07213937 0.0746874 ]
[ 2.92438 0.33646087 0.48980278]
[ 4.1308 0.08558627 0.08634711]
[ 6.94468 0.71801967 0.98840567]
[ 2.7248 0.14950907 0.19408899]
[ 5.89392 0.23684146 0.23756279]
[ 1.24694 0.34040456 0.18172081]
[ 1.5099 0.14780256 0.14409164]
[ 7.24241 0.18409504 0.18429442]
[ 3.49575 0.12190259 0.10648139]
[ 3.13697 0.15849034 0.15939 ]
[ 2.89694 0.36272877 0.39730179]
[ 2.0819 0.17245655 0.27626099]
[ 3.93636 0.0656564 0.06614467]
[ 3.53631 0.14068098 0.17172321]
[ 3.17636 0.20665492 0.20668628]
[ 2.63633 0.15206357 0.28660748]
[ 1.7306 0.25395097 0.6337762 ]
[ 3.29938 0.05445985 0.05463768]
[ 3.46955 0.43179068 0.66132311]
[ nan nan nan]
[ 3.77152 0.27875766 0.28276014]
[ 3.18045 0.26438784 0.28187044]
[ 3.03856 0.15850275 0.15979955]
[ 6.57972 0.07462442 0.0746386 ]
[ 7.81554 0.1637604 0.16379933]
[ 5.04425 0.16337122 0.16430272]
[ 1.65025 0.10175277 0.14958277]] keV
[[ 28.66831 3.2433918]
[ 78.32325 3.12556 ]
[199.53928 5.2998266]
[128.19176 5.6970525]
[ 24.793547 2.2973104]
[120.09137 4.9689746]
[ 30.468397 3.0966108]
[137.75664 5.25023 ]
[126.30015 5.016507 ]
[ 50.421906 2.964098 ]
[101.70913 4.746494 ]
[ 23.14601 2.1740084]
[ 24.244368 1.9738064]
[ 42.87069 3.7267637]
[ 59.63591 4.6716833]
[124.6221 9.576292 ]
[ 36.52462 3.0883944]
[ 78.58259 4.482442 ]
[ 23.679934 2.2644103]
[ 43.11477 3.6073697]
[189.18115 5.613359 ]
[ 32.863426 2.2285726]
[ 38.690826 5.167868 ]
[ 26.395319 2.646696 ]
[ 35.91442 3.2383535]
[ 27.081793 2.5084076]
[ 58.125664 2.954672 ]
[ 34.480453 2.3746781]
[ 20.04925 1.9597924]
[ 39.270515 3.4333043]
[ 75.729904 2.898407 ]
[ 40.68923 3.2910614]
[ 87.781334 4.778909 ]
[ 57.317154 3.9977226]
[ 49.918488 3.82978 ]
[ 40.338364 4.0101438]
[ 99.80225 3.735475 ]
[166.20715 6.2375617]
[ 51.352455 3.1802998]
[ 21.559492 3.837598 ]]
/home/dt237/code/PycharmProjects/XGA/xga/samples/extended.py:425: UserWarning: One of the temperature uncertainty values for XCSSDSS-10401 is more than three times larger than the other, this means the fit quality is suspect.
warn("One of the temperature uncertainty values for {s} is more than three times larger than "
/home/dt237/code/PycharmProjects/XGA/xga/samples/extended.py:436: UserWarning: There are no XSPEC fits associated with XCSSDSS-455
warn(str(err))
The scaling relation generation functions expect the data and uncertainties to be passed in separately, so here we’re just going to split the data I just retrieved from my ClusterSample object.
The scaling relation generating methods support data having either two uncertainties (in which case it will understand them as - and + errors), or just the one set of uncertainties. Part of the data preperation step inside of the scaling relation involves calculating an average uncertainty for a value if it is passed in with two uncertainties. This average uncertainty is what is used to fit the data.
[13]:
# The first column contains the actual temperature values
x_data = temps[:, 0]
# The second and third columns are the uncertainties
x_errs = temps[:, 1:]
# Again the first column contains the richness values
y_data = richnesses[:, 0]
# However this data only has one uncertainty (rather than - and + uncertainties)
y_errs = richnesses[:, 1]
Please make sure you are supplying the x and y data in the correct order, this function needs you to pass the y-data first.
Also, when you fit a scaling relation with LIRA, it automatically uses a power-law in logspace as the model to fit with. This is not true of the other fitting methods, and you will need to supply a model for the fit to use; I suggest importing power_law from xga.models.misc and using that.
There are another couple of differences between the LIRA function and other fitting methods, ODR and Curve Fit both allow you to set start parameters (though you don’t have to), and the LIRA fitting function allows you to tell it how many chains should be run, and with how many steps.
When deciding on what to name your x and y axis, please remember not to put units in the name, XGA will add them itself. Also bear in mind that these names will be passed into matplotlib, so some LaTeX syntax will work:
[14]:
# The x values are temperatures, so selecting an arbitrary normalisation of 4keV
x_norm = Quantity(4, 'keV')
# The y values are richness, which has no unit, but still needs to be in an Astropy quantity
y_norm = Quantity(60, '')
# This uses a LIRA fit to generate the scaling relation
richness_tx_lira = scaling_relation_lira(y_data, y_errs, x_data, x_errs, y_norm, x_norm,
x_name=r'T$_{\rm{x}}$', y_name=r'$\lambda$')
# This uses ODR to generate a scaling relation, note that I have passed in a model function
richness_tx_odr = scaling_relation_odr(power_law, y_data, y_errs, x_data, x_errs, y_norm, x_norm,
x_name=r'T$_{\rm{x}}$', y_name=r'$\lambda$')
/home/dt237/code/PycharmProjects/XGA/xga/relations/fit.py:71: UserWarning: 2 sources have NaN values and have been excluded
warn("{} sources have NaN values and have been excluded".format(thrown_away))
|**************************************************| 100%
[15]:
(richness_tx_lira+richness_tx_odr).view()
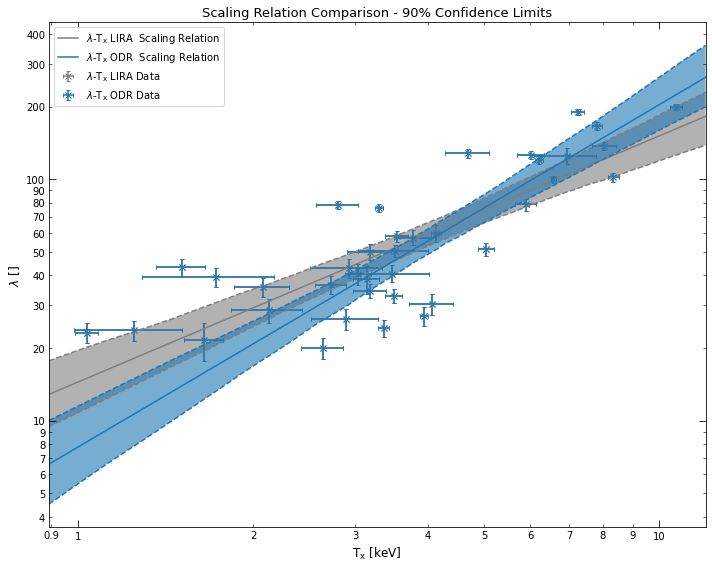
You can also set a range in which you wish a scaling relation to be valid, when you generate it using one of these fitting functions. For instance I generate the same scaling relation we just created, but decide that it is only valid in the temperature range 2-6keV:
[16]:
richness_tx_lira_lim = scaling_relation_lira(y_data, y_errs, x_data, x_errs, y_norm, x_norm,
x_name=r'T$_{\rm{x}}$', y_name=r'$\lambda$',
x_lims=Quantity([2, 6], 'keV'))
richness_tx_lira_lim.view()
/home/dt237/code/PycharmProjects/XGA/xga/relations/fit.py:71: UserWarning: 2 sources have NaN values and have been excluded
warn("{} sources have NaN values and have been excluded".format(thrown_away))
|**************************************************| 100%
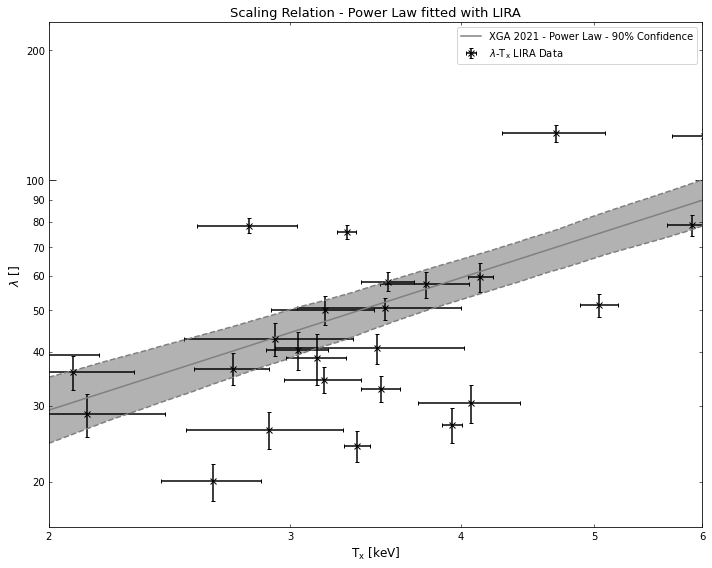
Defining scaling relations from literature
Here I will demonstrate how you can find a relation in literature, and then implement it in a form usable by XGA. This particular scaling relation is actually already implemented in XGA, and is the Arnaud mass-temperature relation that I used in the demonstrations earlier.
It really is as simple as filling out as many of the ScalingRelation arguments as you need. You should note that ‘power_law’ in this case is defined in the XGA models package, and is a function used to generate the fit line that is plotted. ScalingRelation will take its x and y units from the normalisations that are passed in on initialisation (here 5keV for the x axis, and 1e+14M\(_{\odot}\) for the y-axis).
Please don’t include units in the values passed for x_name and y_name, the view() method will add its own units, taken from the astropy normalisation quantities:
[17]:
mt_relation = ScalingRelation(np.array([1.71, 3.84]), np.array([0.09, 0.14]), power_law, Quantity(5, 'keV'),
Quantity(1e+14, 'solMass'), r"T$_{x}$", "E(z)$^{-1}$M$_{500}$",
relation_author='Arnaud et al.', relation_year='2005',
relation_doi='10.1051/0004-6361:20052856',
relation_name='Hydrostatic Mass-Temperature', x_lims=Quantity([1, 12], 'keV'))
mt_relation.view()
